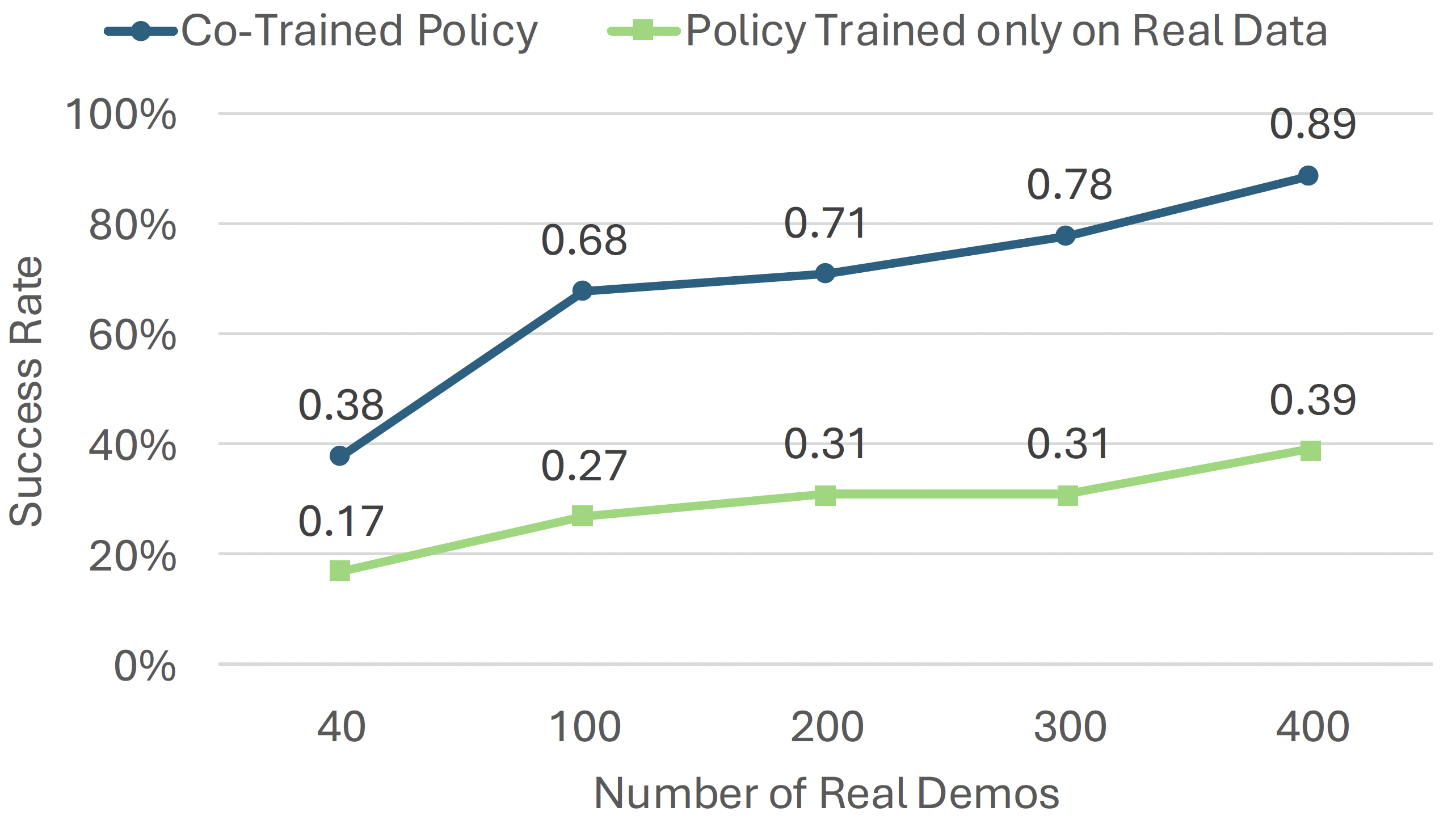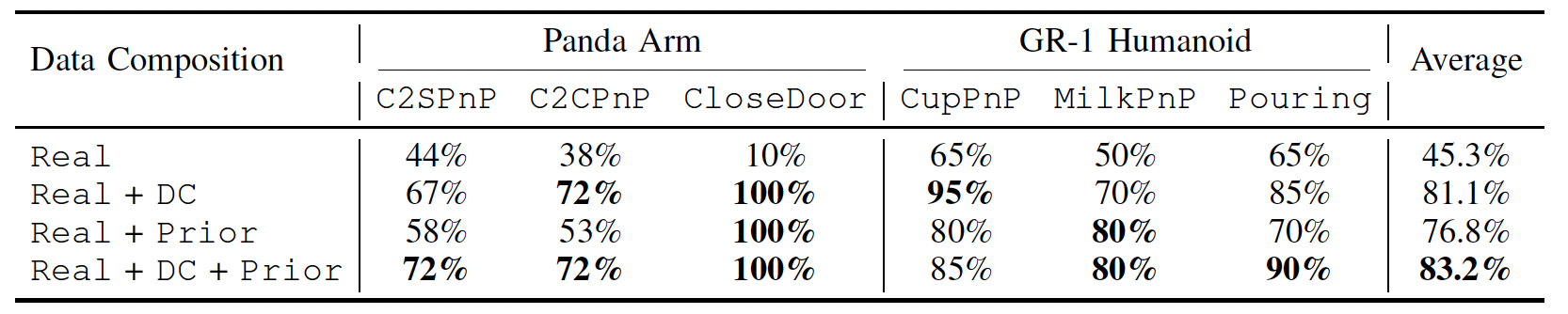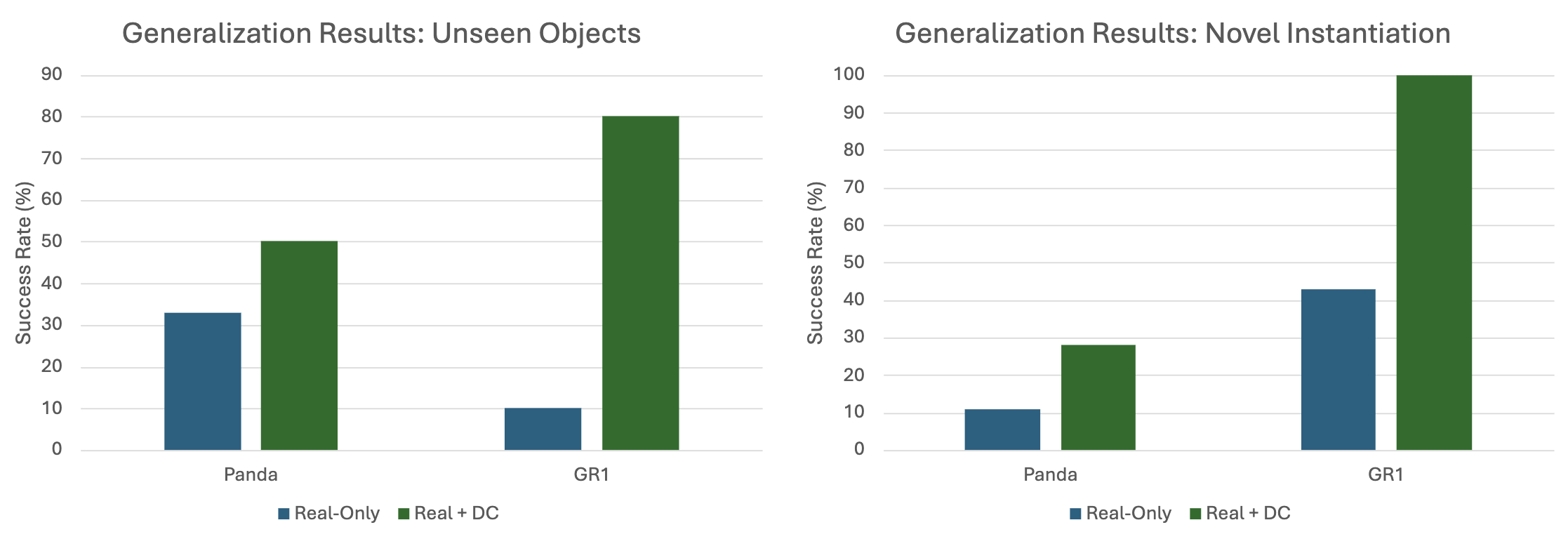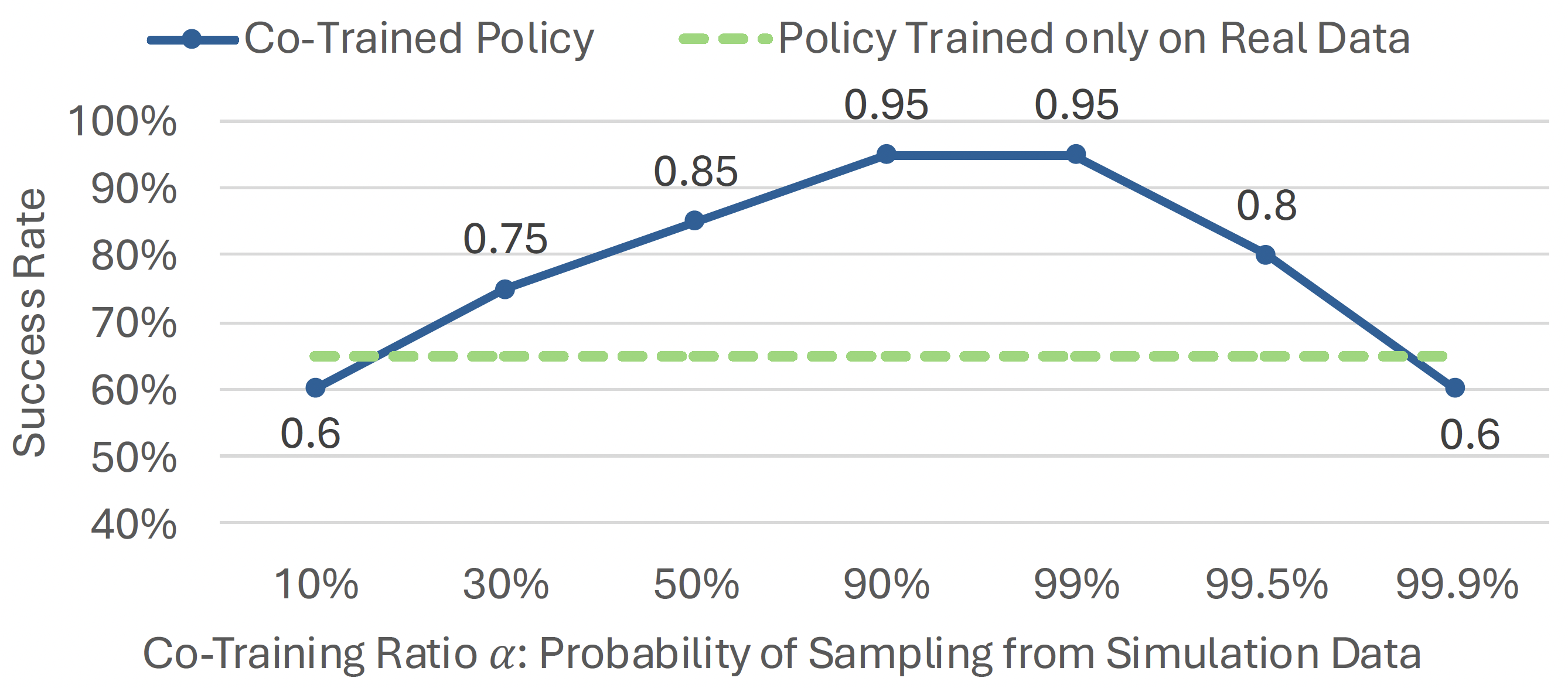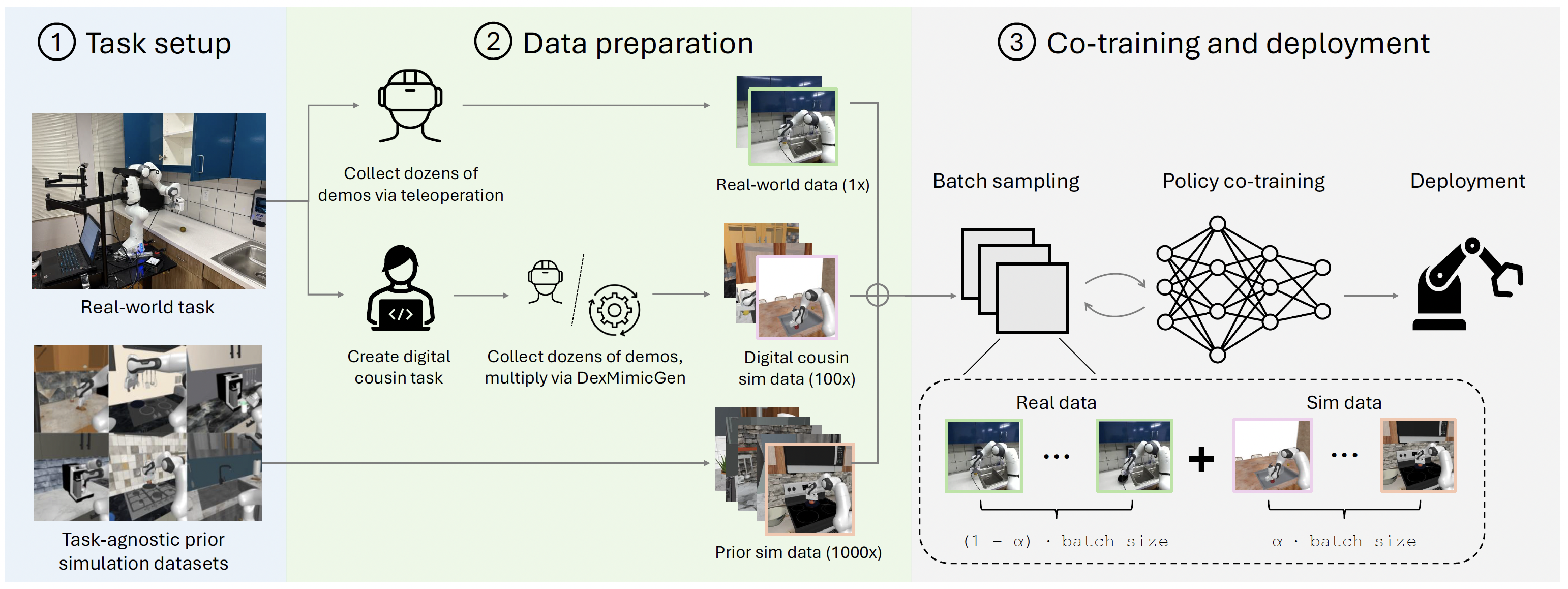
Sim-and-Real Co-training Pipeline. Left: We start with a real-world task in mind and some prior simulation data. Middle: Given real-world tasks and prior simulation data, we can build additional digital cousin tasks that share semantic similarities with their real-world counterparts but may still have discrepancies in visual and physical features. From here we can consolidate prior simulation data, digital cousin data, and real world data. Right: We co-train on a mixture of real-world and simulation data. We sample simulation data according to a sampling ratio of α, and as we show in experiments, this sample ratio is crucial. After training the policy, we deploy the resulting policy directly in the real world.